Title
Implementing regex’s with NFAs
Theorem: Any regex-decidable language is NFA-decidable.
Proof
Inductive proof:
For any regular expression \(R\), we can construct an NFA \(N\) such that \(L(N) = L(R)\).
The base cases of the inductive definition are the base cases of the proof!
If \(R = a\) for some \(a \in \Sigma\), then \(L(R) = \{a\}\) decided by the NFA

If \(R = \emptystring\), then \(L(R) = \{\emptystring\}\) decided by the NFA

If \(R = \emptyset\), then \(L(R) = \{\}\) decided by the NFA

Implementing regex’s with NFAs example: \(\string{(a \cup ab)^* b}\)
 \(\stackrel{\Large \nwarrow}{\large \leftarrow}\) base cases
\(\stackrel{\Large \nwarrow}{\large \leftarrow}\) base cases Don’t bother optimizing by collapsing two states between \(\varepsilon\)-transition. (unsafe in general, even if it happens to work here)
Don’t bother optimizing by collapsing two states between \(\varepsilon\)-transition. (unsafe in general, even if it happens to work here)


Converting NFAs to regex’s
Theorem: Any NFA-decidable language is regex-decidable.
Starting point: “Expression Automata” (or “Generalized NFAs” in Sipser)
Label the transition arrows of an NFA with regular expressions that match substrings of the input rather than individual symbols.

- ❌ \(\emptystring\)
- ❌ \(\string{a}\)
- ❌ \(\string{b}\)
- ✅ \(\string{ba}\)
- ✅ \(\string{bba}\)
- ✅ \(\string{baa}\)
- ❌ \(\string{baaba}\)
- ✅ \(\string{baababa}\)
- ✅ \(\string{baababa}\)
- ✅ \(\string{bbaaababbba}\)
- ❌ \(\string{bbaabab}\)
- ❌ \(\string{bbaababab}\)
Converting NFAs to Regexes
Theorem: Any NFA-decidable language is regex-decidable.
Starting point: “Expression Automata” (or “Generalized NFAs” in Sipser)
Label the transition arrows of an NFA with regular expressions that match substrings of the input rather than individual symbols.
Proof idea:
- Any NFA \(N\) is already a valid expression automaton.
- Incrementally convert \(N\) into a simpler equivalent expression automaton \(E\) of the form:

where \(R\) is a regular expression.
Then \(L(N) = L(E) = L(R)\)!
Converting NFAs to Regexes: Incremental Simplification
We then apply incremental simplifications that remove the states “in the box” one by one:


How does this work in general?
Converting NFAs to Regexes: Incremental Simplification
The final simplification step operates on an EA that looks like:

We can rip state “i” out of the diagram but still accept strings whose computational sequences through it by changing the connection between \(s\) and \(a\):

Both EAs accept exactly strings of the form
- \(w \in L(W)\), or
- \(x y^k z\) for some \(k \in \N\) where \(x \in L(X), y \in L(Y)\), and \(z \in L(Z)\).
Converting NFAs to Regexes: Incremental Simplification
When more than three states remain:
- Select any state other than \(s\) or \(a\) and call it \(i\).
- Iterate over pairs of states \(q\) and \(r\) with transitions \(q \stackrel{a}{\to} i\) and \(i \stackrel{b}{\to} r\) (even if \(q = r\))
- For each of these pairs, transform:
 into:
into: 
- Repeat until only 2 states remain!
Example removing state \(i\)
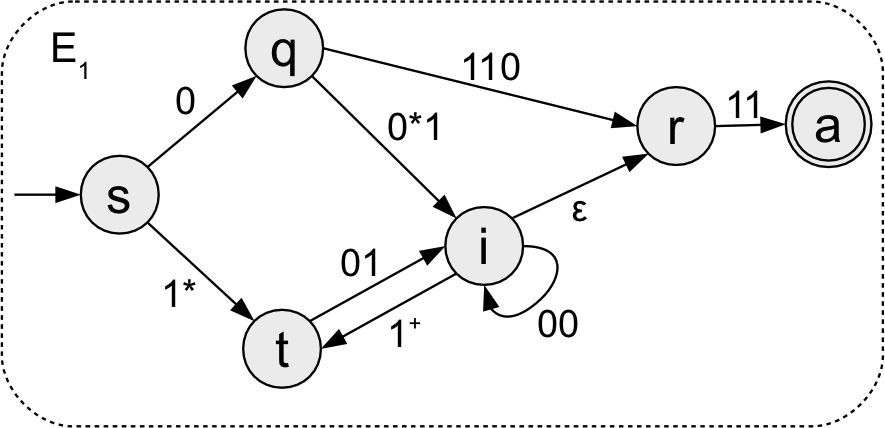
- How to get from \(q\) to \(t\) going through \(i\)? \(0^*1\) (go from \(q\) to \(i\)) \((00)^*\) (loop on \(i\)) \(1^+\) (go from \(i\) to \(t\))
- add new transition \(q \stackrel{0^*1 (00)^* 1^+}{\to} t\)
- How to get from \(q\) to \(r\) going through \(i\)? \(\fragment{0^*1} \fragment{(00)^*} \fragment{\emptystring} \fragment{= 0^*1 (00)^*}\) OR directly follow \(q \stackrel{110}{\to} r\).
- replace existing \(q \stackrel{110}{\to} r\) transition with \(q \stackrel{0^*1(00)^* \cup 110}{\to} r\)
- How to get from \(t\) to \(r\) going through \(i\)? \(\fragment{01 (00)^*}\)
- add new transition: \(t \stackrel{01(00)^*}{\to} r\)
- How to get from \(t\) to \(t\) going through \(i\)? \(\fragment{01 (00)^* 1^+}\)
- add new self-transition: \(t \stackrel{01(00)^*1^+}{\to} t\)
