Title
Simple reduction example: \(\probIndSet\) to \(\probClique\)
Recall the the \(k\)-clique problem (clique = set of nodes with edges between all pairs): \[ \probClique = \setbuild{\encoding{G, k}}{ G \text{ is an undirected graph with a } k\text{-clique}} \]
We now introduce a closely related problem, the \(k\)-independent set problem (independent set = set of nodes with edges between no pairs): \[ \probIndSet = \setbuild{\encoding{G, k}}{ G \text{ is an undirected graph with a } k\text{-independent set}} \]
Given input \(\encoding{G_i, k}\) for \(\probIndSet\),
how can we convert it to input \(\encoding{G_c, k}\) for \(\probClique\) such that:\[ \encoding{G_i, k} \in \probIndSet \iff \encoding{G_c, k} \in \probClique \]


Recall: Example reduction to bound complexity of \(\probClique\)
from itertools import combinations as subsets
def reduction_from_independent_set_to_clique(G: Graph[Node], k: int) -> tuple[Graph[Node], int]:
V, E = G
Ec = [ {u,v} for (u,v) in subsets(V,2)
if {u,v} not in E and u!=v ]
Gc = (V, Ec)
return (Gc, k)
# Hypothetical polynomial-time algorithm for Clique
def clique_algorithm(G: Graph[Node], k: int) -> bool:
raise NotImplementedError
# Polynomial-time algorithm for IndependentSet
# that calls clique_algorithm as a subroutine
def independent_set(G: Graph[Node], k: int) -> bool:
Gp, kp = reduction_from_independent_set_to_clique(G, k)
return clique_algorithm(Gp, kp)
- We conclude that \(\probIndSet \le^\P \probClique\).
- \(\probClique\) is at least as hard as \(\probIndSet\).
- Since
reduction_from_independent_set_to_cliquealso happens to work in the other direction
(just complement again!), we can conclude also: \(\probClique \le^\P \probIndSet\).
Implications of \(A \le^\P B\)
Let’s now formalize what we mean by “\(B\) is at least as hard as \(A\)”
Theorem: If \(A \le^\P B\) and \(B \in \P\), then \(A \in \P\). (“if \(B\) is easy, then \(A\) is easy”)
Proof:
Since \(B \in \P\), there is an algorithm \(M_B\) for \(B\) running in time \(O(n^k)\) for some constant \(k\).
Since \(A \le^\P B\), there is a reduction \(f\) from \(A\) to \(B\) running in time \(O(n^c)\) for some constant \(c\).
We can construct an algorithm \(M_A\) deciding \(A\) simply by composing \(f\) and \(M_B\): \[ M_A(x) = M_B(f(x)) \]
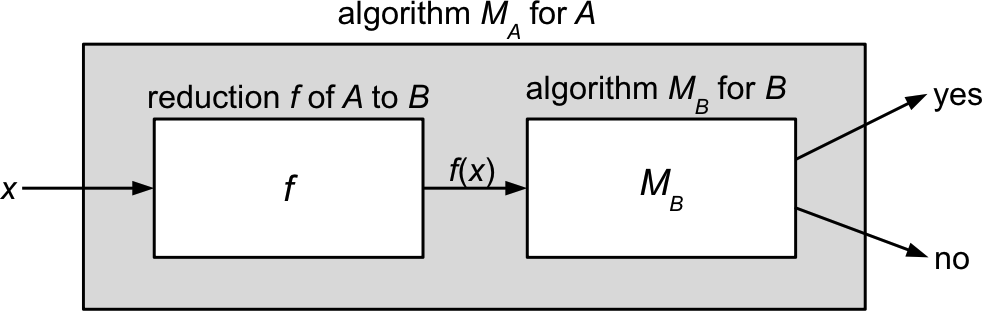
What is the time complexity of \(M_A\)? Let \(n = |x|\).
- \(O(n^c)\) for \(f(x)\), plus \(O(m^k)\) for \(M_B(f(x))\), where \(m = |f(x)|\).
- Since \(m = O(|x|^c)\), the full time complexity is: \[ O(n^c) + O(O(|x|^c)^k) \fragment{= O(n^c + n^{ck})} \fragment{= O(n^{ck})} \fragment{\quad \implies \quad A \in \P} \]