Title
Example gadget construction
\[ \phi = (x \lor x \lor y) \land (\overline{x} \lor \overline{y} \lor \overline{y}) \land (\overline{x} \lor y \lor y) \hspace{6em} \]
Is this formula satisfiable?
Yes: \(x = 0, y = 1\).
\(\encoding{\phi} \in \probThreeSAT\) iff we can pick
one literal from each clause
to set to “1” without conflicts!



Reductions between problems of different types: \(\probThreeSAT\)
Theorem: \(\probThreeSAT \le^\P \probIndSet\).
Proof:
Given a 3-CNF formula \(\phi\): \[ \phi = (a_1 \lor b_1 \lor c_1) \land (a_2 \lor b_2 \lor c_2) \land \ldots \land (a_k \lor b_k \lor c_k) \] we produce a pair \((G, k)\) such that: \[ \encoding{\phi} \in \probThreeSAT \; \iff \; \encoding{G, k} \in \probIndSet \]
Set \(k\) equal to the number of clauses in \(\phi\).
- Create one node in \(G\) for each literal in \(\phi\).
- Create edge {u, v} in \(G\) if and only if:
- \(u\) and \(v\) correspond to literals in the same clause (triple), or
- \(u\) is labeled \(x\) and \(v\) is labeled \(\overline{x}\) for some variable \(x\) (or vice versa).
- \(u\) and \(v\) correspond to literals in the same clause (triple), or
We can generate these edges in polynomial time by looping over all pairs of nodes (\(O(|V|^2)\))
and checking the these two conditions by scanning through \(\phi\). (Python code in lecture notes)
Reductions between problems of different types: \(\probThreeSAT\)
Proof that \(\encoding{\phi} \in \probThreeSAT \; \iff \; \encoding{G, k} \in \probIndSet\):
- \(\phi\) satisfiable \(\implies\) \(G\) has a \(k\)-independent set.
- Suppose \(\phi(w) = 1\) (\(w\) is a satisfying assignment)
- Then \(w\) makes at least one literal in each clause true.
- Construct \(k\)-independent set \(S\) by selecting one node from each clause labeled by a true literal. (break ties arbitrarily)
- For every \(u, v \in S\):
- in different triples (so not connected by edge type 1)
- not labeled by variables \(a\) and \(\overline{a}\) respectively (so not connected by edge type 2)
- So \(u\) and \(v\) are not connected by an edge, so \(S\) is a \(k\)-independent set in \(G\)!
- \(G\) has a \(k\)-independent set \(\implies\) \(\phi\) satisfiable
- Given an \(k\)-independent set \(S\), choose assignment \(w\) by setting variable \(a\) to true if some node in \(S\) is labeled \(a\) and false if labeled \(\overline{a}\).
- If some neither literal \(a\) nor \(\overline{a}\) appears in \(S\), set \(a\) arbitrarily.
- Every node in \(S\) must correspond to a different clause due to edge type \(1\).
- Since there are \(k\) clauses and \(|S| = k\), each clause must have at least one true literal marked.
- The edges in \(G\) between nodes for “conflicting” literals mean \(w\) does not set \(a\) and \(\overline{a}\) to true at the same time for any \(a\), so \(w\) is a satisfying assignment for \(\phi\)!
- Given an \(k\)-independent set \(S\), choose assignment \(w\) by setting variable \(a\) to true if some node in \(S\) is labeled \(a\) and false if labeled \(\overline{a}\).
Reductions don’t themselves solve problems!
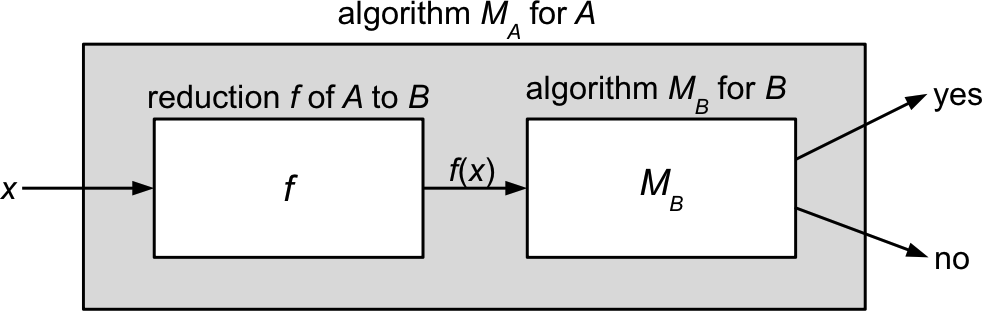
- A reduction \(f\) is just a (polynomial-time) algorithm
- It enables solving problem \(A\) in terms of an algorithm for problem \(B\).
- However, \(f\) does not itself solve either problem!
- It transforms an instance of problem \(A\) (e.g., a formula for \(\probThreeSAT\))
into an instance of problem \(B\) (e.g., a graph for \(\probIndSet\)). - It preserves the “yes” or “no” answer to the original problem
(but does not provide the answer itself).
- It transforms an instance of problem \(A\) (e.g., a formula for \(\probThreeSAT\))